а вот Стоку усиливаться особо нечем. Ну железо посерьезней, но еще на ход глубже посчитает ... Сток это уже можно сказать отыгранный силиконовый гросс.
Да ладно, вы чего? Он с каждой версией усиливается на 50-100 пунктов. То есть следующая версия будет громить нынешнюю примерно с тем же счетом, может, чуть меньше
А вдруг опровержение найдет? При монте-карлах просчеты неизбежны
Но тут то не простой монтекарла, а умный, продукт самообучения.
настораживает, что лучший счётчик как Стокфиш не находит опровержений, может Альфа тоже недурно считает, но только то, что стоит свеч вслед за вероятностными рекомендациями
Я Вам навскидку могу сказать, что 28 - 0 если выкинуть 72 ничьи говорит об очень большой разности в вероятности одержать победу.onedrey wrote:
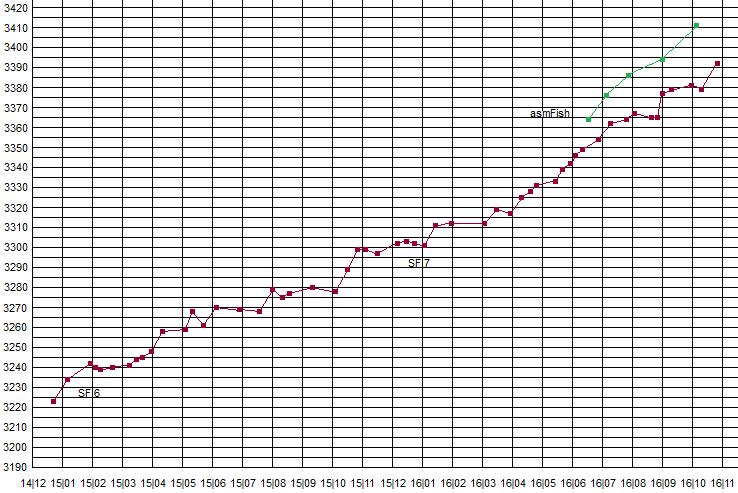
Кстати, вот прогресс за этот год Стокфиша, которому "усиливаться особо нечем". Где-то 160 пунктов Эло прибавил
Ну значит тут я ошибся. Но еще раз повторюсь это тупиковый путь в любом случае. Таблицы, дебютные базы, ускорение железа все это нельзя сравнивать с принципиально новым подходом, который позволил компьютеру самообучиться и играть в абсолютно другом стиле чем обычные движки.
Так тестирование проводится на одном и том же железе, без дебютных баз. Это сам движок лучше играет.
А вот насчет влияния передового железа на победу Альфы все не так однозначно.
Вообще, только вдумайтесь, маленький движочек (1 Мб) "голыми руками" играет на устаревшем железе против передового скорострельного монстра, оснащенного гигабайтными базами партий, и уступает всего 100 Эло.
Откуда Вы это взяли. Никаких баз партий у Альфы нет. Есть осмысление опыта игры против себя самой, в виде коэффициентов нейросети. Все эти коэффициенты легко уложаться в мегабайты.onedrey wrote:
Так тестирование проводится на одном и том же железе, без дебютных баз. Это сам движок лучше играет.
Что разработчики пишут, какие новые фичи алгоритма обеспечивают линейный рост?
Я не углублялся в вопрос, что именно они там улучшают. Насколько могу судить, это в основном сотни мелких изменений, которые вносятся и тестируются, в случае успеха оставляются. Там большое сообщество. Какие-то улучшения чисто программистские и мне непонятные, типа оптимизации кода, какие-то новые шахматные функции тоже испытываются, а старые совершенствуются
А откуда вы взяли, что никаких баз нет? Насколько я понимаю, у нее есть все сыгранные партии с расставленными оценками. И даже не партии, а целые деревья анализов, куда вошли не только сыгранные ходы, но и проанализированные
А разве дебюты не сохраняются? Я даже где-то табличку видел тестовых партий со Стокфишем...
В смысле? Партии, которые были сыграны они очевидно могут куда то записывать. Но алгоритм эволюции параметров сети просто на каждой итерации меняет веса, сами партии уже потом больше не используются. Я исхожу из предположения, что они использовали стандартный в таких задачах SGD.
у меня смутное ощущение об алгоритме: "рисункам" позиций навешивает веса (во время самообучения) в зависимости от их успеха и колышут его в дальнейшем только позиции с большим весом
Что бы там альфа не наиграла, к каким бы выводам не пришла, - всё равно староиндийка и грюнфельд рулят, да и новоиндийка не сказала последнего слова.
А я к своему стыду только названия и знаю. Никак не могу себя заставить выучить хоть какой то дебют. Вот попробовал дебют Эльшада выучить, и то не смог ничего понять чтобы запомнить.
С точки зрения борьбы против Альфы имхо было бы интересно увидеть ее игру против каких нибудь боковых дебютов типа 1.a4, которые она видимо отмела на ранней стадии обучения, но возможно вселдствии этого настройки ее нейросети пошаливают в дальних позициях, которые в таких дебютах возникают.
В смысле? Партии, которые были сыграны они очевидно могут куда то записывать. Но алгоритм эволюции параметров сети просто на каждой итерации меняет веса, сами партии уже потом больше не используются. Я исхожу из предположения, что они использовали стандартный в таких задачах SGD.
Не исключено, что и оптимальные маршруты в виде дебютной книги тоже сохраняются. Не зря же 9 часов жгли электричество
не могу просечь пока как, в принципе, типы/"рисунок" позиций увязаны с их весами в памяти нейросети, как та решает к какому типу/весу отнести текущую позицию?
Не исключено, что и оптимальные маршруты в виде дебютной книги тоже сохраняются. Не зря же 9 часов жгли электричество
Нет я хоть и не понял до конца их подход, но понял достаточно чтобы быть уверенным на 100% в отсутствии дебютной книги и базы оптимальных маршрутов. Это будет в принципе противоречить всей логике алгоритма.
Хайдук wrote:
не могу просечь пока как, в принципе, типы/"рисунок" позиций увязаны с их весами в памяти нейросети, как та решает к какому типу/весу отнести текущую позицию?
Ну это то легко как раз. Почитайте например их статью, секцию Representation
The input to the neural network is an N × N × (MT + L) image stack that represents state using a concatenation of T sets of M planes of size N × N. Each set of planes represents the board position at a time-step t − T + 1, ..., t, and is set to zero for time-steps less than 1. The board is oriented to the perspective of the current player. The M feature planes are composed of binary feature planes indicating the presence of the player’s pieces, with one plane for each piece type, and a second set of planes indicating the presence of the opponent’s pieces. For shogi there are additional planes indicating the number of captured prisoners of each type. There are an additional L constant-valued input planes denoting the player’s colour, the total move count, and the state of special rules: the legality of castling in chess (kingside or queenside); the repetition count for that position (3 repetitions is an automatic draw in chess; 4 in shogi); and the number of moves without progress in chess (50 moves without progress is an automatic draw). Input features are summarised in Table S1. ...