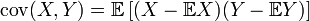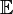Я тут не профессионал, то если я правильно понимаю, то в двух словах, это обобщенная методика построения линейных приближений для многомерных наборов данных.
Грубо говоря у Вас есть вектор переменных. Эти переменные зависят друг от друга. Вам, как биологу, должен быть близок такой пример. Если мы прогенотипировали человека, то переменные будут генотипы. Генотипы в близких друг к другу позициях будут коррелированы. Далее производится линейная трансформация данных, которая переводит эти переменные в новые уже не кореллированные. Каждая новая переменная есть линейная комбинация оригинальных переменных. Трансформация делается так, что первая новая переменная имеет наибольшую вариацию в наборе данных, итд. Тоесть Вы получаете возможность малым числом переменных описывать вариацию. Возвращаясь к ДНК, таким образом первая переменная будет например отличать расы. Вторая переменная будет отличать южных африканцев от северных итд ...
С математической точки зрения, Вы делаете сингулярное разложение корреляционной матрицы.
Ув.РР меня поправит, ежели что не так.
Т.е если, допустим, в 3-мерном пространстве есть некая летающая тарелка
Тогда с помощью Principal component analysis можно например построить плоскость, в которой эта тарелка лежит. Координаты линейно преобразуются, чтобы эта плоскость стала XY
Или есть тарелка в виде длинной сигары. Тогда строится ось ея и координаты преобразуются так, чтобы эта ось стала Х.
Все это относится к множеству точек конечно.
такой пример. Если мы прогенотипировали человека, то переменные будут генотипы. Генотипы в близких друг к другу позициях будут коррелированы. Далее производится линейная трансформация данных, которая переводит эти переменные в новые уже не кореллированные. Каждая новая переменная есть линейная комбинация оригинальных переменных. Трансформация делается так, что первая новая переменная имеет наибольшую вариацию в наборе данных, итд. Тоесть Вы получаете возможность малым числом переменных описывать вариацию. Возвращаясь к ДНК, таким образом первая переменная будет например отличать расы. Вторая переменная будет отличать южных африканцев от северных итд ...
Если можно, то хотелось бы разобраться с этим примером.
Допустим у нас есть четыре текстовых файла с четырьмя геномами. Каждый файл размером в гигабайт:
Если можно, то хотелось бы разобраться с этим примером.
Допустим у нас есть четыре текстовых файла с четырьмя геномами. Каждый файл размером в гигабайт:
attgtagatg...
attgtatatg...
agtgtagatg...
attgtagatt...
Что дальше с ними делается в этом методе?
Вот грубая апроксимация процесса:
1)Compare genomes to reference genome, e.g.
12345678910
ATTGTAGATG - reference
attgtagatg...
attgtatatg...
agtgtagatg...
attgtagatt...
2)For positions with observed variants output genotypes
pos 2 0,0,1,0...
pos 7 0,1,0,0...
pos 10 0,0,0,1,...
3) perform PCA on matrix of genotypes (compute eigen vectors and eigen values of covariance matrix.)
4) explore what first,second,... principal component correlates with. In case if these genomes are human and from different races first component will likely correlate with race. Also, you can perform a statistical test of significance of eigen value to see if there is anything non-random to begin with.
На мой взгляд, использовать PCA для анализа символьных последовательностей очень опасно. Дело в том, каждая компонента вектора должна содержать "однородные" данные. Например, если это вес пациента, то это вес пациента во всех образцах. Если это интенсивность на определенной частоте спектра, то это более-менее верно для всех образцов. И т.д.
В символьной последовательности, особенно в ДНК, этого обычно нет. Начнем с того, что начало последовательности выбрано из каких-то соображений. Если эти соображения верны, то ОК, а если у каждого образца есть случайная ошибка в определении начала последовательности?
Но более серьезно то, что длина последовательностей со сходной функцией не есть величина постоянная. Длина белков, даже гомологичных варьирует, я уж не говорю про длину мРНК у эукариотов, длина промотера тоже не постоянна.
То есть, даже правильно выравняв стартовые позиции последовательностей, Вы не можете гарантировать, что последние позиции будут функционально эквивалентны. О каком PCA тут можно говорить.
С ходу я даже не могу придумать пример когда использование PCA оправдано, хотя, думаю, такие примеры могут существовать.
Дело в том, каждая компонента вектора должна содержать "однородные" данные.
В случае с ДНК она и содержит. procrastinator wrote:
То есть, даже правильно выравняв стартовые позиции последовательностей, Вы не можете гарантировать, что последние позиции будут функционально эквивалентны. О каком PCA тут можно говорить.
С ходу я даже не могу придумать пример когда использование PCA оправдано, хотя, думаю, такие примеры могут существовать.
Дело в том, каждая компонента вектора должна содержать "однородные" данные.
В случае с ДНК она и содержит.
Не совсем так, данные в каждой позиции берутся из того же множества, да в это плане однородные. Но я имел в виду другое. Например, один образец может начинаться с первой позиции кодона, другой - со второй, а третий может быть взят из некодирующей области. Это все равно что Вы решили применить PCA к временным рядам, но начало каждого ряда выбрано с неизвестной ошибкой. Более того некоторые из них оказались короче других.
procrastinator wrote:
То есть, даже правильно выравняв стартовые позиции последовательностей, Вы не можете гарантировать, что последние позиции будут функционально эквивалентны. О каком PCA тут можно говорить.
С ходу я даже не могу придумать пример когда использование PCA оправдано, хотя, думаю, такие примеры могут существовать.
Principal component analysis
11 Апр 2013 20:32 #10
procrastinator wrote:
Не заметил в этой статье PCA в применении к последовательностям.
А оно между тем есть. Просто последовательности не начинаются со случайных позиций, как Вы описываете, а имеют начало и конец по отношению к некоему стандартному геному.
Поэтому каждый нуклеотид в заданной позиции (по отношению к стандарту) является вполне себе переменной. Если в данной позиции у рассматриваемой популяции стоит один и тот же нуклеотид, то мы эту позицию исключаем из рассмотрения, а если наблюдается вариация, то ставим в соответствие числа. Например 0,1,2 по числу аллелей несовподающих со стандартом. У меня к сожалению нет времени уходить в детали, но я попробую дать ссылку на какой нибудь подробный обзор. procrastinator wrote:
Например, один образец может начинаться с первой позиции кодона, другой - со второй, а третий может быть взят из некодирующей области.
Ну в таком случае конечно же применять PCA не имеет смысла. Но последовательности можно align.
Principal component analysis
12 Апр 2013 17:02 #12
PP wrote:
Вот грубая апроксимация процесса:
1)Compare genomes to reference genome, e.g.
12345678910
ATTGTAGATG - reference
attgtagatg...
attgtatatg...
agtgtagatg...
attgtagatt...
2)For positions with observed variants output genotypes
pos 2 0,0,1,0...
pos 7 0,1,0,0...
pos 10 0,0,0,1,...
3) perform PCA on matrix of genotypes (compute eigen vectors and eigen values of covariance matrix.)
4) explore what first,second,... principal component correlates with. In case if these genomes are human and from different races first component will likely correlate with race. Also, you can perform a statistical test of significance of eigen value to see if there is anything non-random to begin with.
Застрял на пункте (3). Читаю про covariance matrix. До principal components еще не добрался. Так вот про covariance matrix нам как-то непонятно пишут:
In probability theory and statistics, a covariance matrix (also known as dispersion matrix or variance covariance matrix) is a matrix whose element in the i, j position is the covariance between the i th and j th elements of a random vector (that is, of a vector of random variables). Each element of the vector is a scalar random variable, either with a finite number of observed empirical values or with a finite or infinite number of potential values specified by a theoretical joint probability distribution of all the random variables.
Есть более простое объяснение что такое covariance matrix?
Если вот построить такую матрицу для моего примера, то как она будет выглядеть?
Вот по-русски тоже не очень понятно:
Ковариационная матрица (или матрица ковариаций) в теории вероятностей — это матрица, составленная из попарных ковариаций элементов одного или двух случайных векторов.
Таак... а ковариация у нас вот что:
где
— оператор математического ожидания.
И как это в применениии к нашему примеру?
Principal component analysis
12 Апр 2013 22:53 #13
mittelspiel wrote:
И как это в применениии к нашему примеру?
Напрямую. Допустим мы хотим посчитать элемент матрицы, соответствующий ковариации рядов pos 2 и pos 7. Тогда
X={0,0,1,0}, Y={0,1,0,0} E(X) = 1/4 E(Y)=1/4 вместо мат. ожидания берем среднее значение. Вычитаем из элементов X и Y средние значение, потом перемножаем элементы, считаем среднее и получаем элемент матрицы. Только на самом деле мы в конце мы не усредняем, а делим на (N-1) так как мы мат. ожидания X и Y заменили на их средние значения.
Principal component analysis
13 Апр 2013 18:50 #14
PP wrote:
mittelspiel wrote:
И как это в применениии к нашему примеру?
Напрямую. Допустим мы хотим посчитать элемент матрицы, соответствующий ковариации рядов pos 2 и pos 7. Тогда
X={0,0,1,0}, Y={0,1,0,0} E(X) = 1/4 E(Y)=1/4 вместо мат. ожидания берем среднее значение. Вычитаем из элементов X и Y средние значение, потом перемножаем элементы, считаем среднее и получаем элемент матрицы. Только на самом деле мы в конце мы не усредняем, а делим на (N-1) так как мы мат. ожидания X и Y заменили на их средние значения.
Пока не понимаю. Ну, допустим, понятно как по этой формуле посчитать матрицу ковариации для двух генотипов. А как для всех сразу?
Ипока не дошел до понятия principal components все равно.
Principal component analysis
13 Апр 2013 20:44 #15
mittelspiel wrote:
А как для всех сразу?
Ипока не дошел до понятия principal components все равно.
Вот берете и для всех пар генотипов и считаете коэффициенты получая симметричную матрицу МхМ, где М число генотипированных позиций. Потом находите собственные векторы этой матрицы и получаете PCA. Но руками самому ничего делать не надо. Для этого есть стандартные пакеты. Засовываете туда исходную матрицу и получаете на выходе principal components.
Principal component analysis
13 Апр 2013 23:17 #16
PP wrote:
mittelspiel wrote:
А как для всех сразу?
Ипока не дошел до понятия principal components все равно.
Вот берете и для всех пар генотипов и считаете коэффициенты получая симметричную матрицу МхМ, где М число генотипированных позиций. Потом находите собственные векторы этой матрицы и получаете PCA. Но руками самому ничего делать не надо. Для этого есть стандартные пакеты. Засовываете туда исходную матрицу и получаете на выходе principal components.
Так каждый генотип с каждым сравнивать? тогда получается матрица MxNxN, где N - число генотипов?
И хорошо, чисто математически операцию нахождения собственных векторов я понимаю, понятно что есть математические пакеты. Но чему они (эти цифры в собственных векторах) будут потом соответствовать, как их потом обратно конвертировать в биологическую информацию, например, в Вашем примере в "расу"?
Principal component analysis
14 Апр 2013 08:30 #17
mittelspiel wrote:
чему они (эти цифры в собственных векторах) будут потом соответствовать, как их потом обратно конвертировать в биологическую информацию, например в ... "расу"?
Вот-вот, вопрос в том какие значительные достижения были здеалны анализом principal components?
Principal component analysis
15 Апр 2013 16:26 #18
mittelspiel wrote:
Так каждый генотип с каждым сравнивать? тогда получается матрица MxNxN, где N - число генотипов?
Просто NxN.
Вот-вот, вопрос в том какие значительные достижения были здеалны анализом principal components?
Зависит от того, что называть значительным достижением. Просто один из многих методов работы с данными высокой размерности. А уж как интерпретировать принципиальные компоненты зависит от каждой конкретной задачи и метод вовсе не является универсально полезным.
Грубо говоря у Вас есть вектор переменных. Эти переменные зависят друг от друга. Вам, как биологу, должен быть близок такой пример. Если мы прогенотипировали человека, то переменные будут генотипы. Генотипы в близких друг к другу позициях будут коррелированы. Далее производится линейная трансформация данных, которая переводит эти переменные в новые уже не кореллированные. Каждая новая переменная есть линейная комбинация оригинальных переменных. Трансформация делается так, что первая новая переменная имеет наибольшую вариацию в наборе данных, итд. Тоесть Вы получаете возможность малым числом переменных описывать вариацию. Возвращаясь к ДНК, таким образом первая переменная будет например отличать расы. Вторая переменная будет отличать южных африканцев от северных итд ...
С математической точки зрения, Вы делаете сингулярное разложение корреляционной матрицы.
Хайдук wrote:
Что в области ДНК и генной регуляции оказалось принципиальными компонентами?
Сорри, но лень мне углубляться. Выходите на литературу если интересно.
Тогда, если можно, НЕГЛУБОКО, но интересно:
из МУХИ слона сколькиПРОЦЕНТНО можно получить?
Гостям сие 140% полезно, ведь вся наука не ради самой науки ТВОРИТСЯ
Зависит от того, что называть значительным достижением. Просто один из многих методов работы с данными высокой размерности. А уж как интерпретировать принципиальные компоненты зависит от каждой конкретной задачи и метод вовсе не является универсально полезным.
Это тлько инфолиочервяки или/и грибы позволяют предположить что может быть ОБЩЕМЕТОДОЛОГИЧЕСКИЙ всеэффективный и всеприемлемый подход
с верификацией
фальсификацией или
спекуляризацией
примитивно просто предельно теоретически на ЭВМ или мысленно ПРОВЕРЯЕМЫЙ легко на практике... З павагай к ПП_Ха и ТС (& ГИ)